爬虫:写在前面
一些理解
网络爬虫:爬虫完整的名字应该叫网络爬虫,因为它依赖于HTTP协议获取数据,浏览器上Web应用的基础,顾名思义需要网络。
所见即所得:另外,浏览器的原则是所见即所得,你在浏览器上看到的东西,都是服务器通过网络发到本地的,因此能见到的就能够爬到。
Robots.txt:在爬取之前应该仔细阅读网站设置的爬虫规则,上面有详细的允许和不允许爬的内容。
爬虫基本运行过程一般是三个步骤:请求数据,过滤数据,保存数据。
一. Requests-概述
Request是Python的第三方库,用于网络请求并接收返回的数据,你需要在Python的虚拟环境中安装使用。
Request帮助你发送网络请求,同时你可以自定义Request携带的参数。
另外,Request模块接收响应请求的数据,并把Response作为函数的返回。
如果你想实现一个爬虫,对返回的网页文件进行Xpath/正则表达式解析,并将你需要的内容存储即可。
二. Request基础
1. 下载&安装
pip/pip3 install requests
2. Request库
关于request
request支持各种HTTP方法,同时你可以指定请求所携带的内容。
- 获取响应文件
response = request.get(url)
- 带上请求头headers
response = request.get(url, headers = headers)
- 伪装浏览器代理,避免反爬虫
*如果你向https://www.douban.com/发送请求,响应码为418,
headers = {
'user-agent':
'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Mobile Safari/537.36 Edg/116.0.1938.69'
}
关于response
你可以定义参数response(或者其他名字)接收request的返回。
- 返回响应状态码
status_code = response.status_code
- 返回网页HTML文件
content = response.content
了解更多
三. 代码实例
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
if(response.status_code == 200):
print(response.content)
else:
print(response.status_code)
四. 问题?
1. response.text/response.content返回中文?
你可以使用 response.content.decode(‘utf-8’) 使得content正常的显示中文内容。
另外, response.text 使用推测的解码格式(ISO-8859-1),相当于 response.content.decode(response.encoding) 。
2. 418 | I’m a teapot?
大概:服务器表示我是一个茶壶,需要咖啡的话别找我。
当然,具体意思需要结合实际场景。
如果某些网站反爬虫,那么如果你不表示你的代理是浏览器的话,你也会收到418。
解决方案也很简单,使用 headers{‘user-agent’:’xxx’} 来声称你使用浏览器代理访问网站。
一. Xpath
1. Xpath基础
Xpath适用于解析HTML格式文件,并且语法及其简介。
2. 对str对象使用Xpath
对于一般的HTML格式响应对象 response.text() 是字符串类型,因此在使用之前: from lxml import etree
3. Xpath语法
这里先举个例子(也是我开始学爬虫的测试网站)
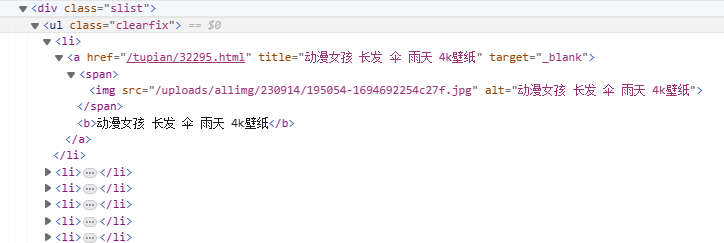
如果你想拿到 a标签 的href属性://div/ul/li/a/@href
如果你想拿到 img标签 的src属性://div/ul/li/a/span/img/@src
如果你想拿到 b标签 的内容://div/ul/li/a/b/text()
//div能够锁定所有div标签,这也是经常使用的Xpath开头,当然你也可以明确定位一个标签//div[@class=’slist’]
下面是详细语法
/:子标签
//:子孙标签
@:取属性
text():取内容
二. JSON
1. JSON基础
json用于解析json类型格式响应,这是非常普遍的,在异步加载的网页中,很多后端数据通过json格式传到前端进行渲染,得到浏览器显示的HTML文件。比如微博。
2. Python字典处理JSON
Python字典和Java对象很相似,Json(JavaScript Object Notation)也可以通过python字典进行处理。
comment_json = json.loads(response.text)
3. Python字典语法
这个很简单…
额..还是记一下吧
user = {
'uid': ''
'username': ''
'password': ''
'friends': []
}
dict[“xxx”]:取字典中xxx
三. BS4
1. bs4基础
2. 引入bs4
from bs4 import BeautifulSoup
3. bs4语法
soup = BeautifulSoup(resp.content, 'html.parser')
tag_div = soup.find_all("div",class_='result c-container xpath-log new-pmd')
link = i.get('mu')
一. TXT
代码比较简单,看一下应该就懂了…
对于列表
# 是否保存
save = input("共" + str(len(comment_list)) + "条记录,保存到commen.txt(y/n):")
if (save == "y" or save == "Y"):
print("正在写入中...")
with open("comment.txt", "w", encoding="utf-8") as f:
for comment in tqdm(comment_list):
f.writelines(comment + "\n")
对于字典
# 是否保存?
save = input("共" + str(len(list_dic_blog)) + "条记录,保存到blog.txt(y/n):")
if (save == "y" or save == "Y"):
with open("blog.txt", "w", encoding='Utf-8') as f:
for dic_blog in tqdm(list_dic_blog):
f.writelines(str(dic_blog) + "\n")
二. JSON
json_str = json.dumps(the_dict,indent=4,ensure_ascii=False)
with open(file_name, 'w') as json_file:
json_file.write(json_str)
三. Excel
# -*- coding: utf-8 -*-
import xlsxwriter as xw
def xw_toExcel(data, fileName): # xlsxwriter库储存数据到excel
workbook = xw.Workbook(fileName) # 创建工作簿
worksheet1 = workbook.add_worksheet("sheet1") # 创建子表
worksheet1.activate() # 激活表
title = ['序号', '酒店', '价格'] # 设置表头
worksheet1.write_row('A1', title) # 从A1单元格开始写入表头
i = 2 # 从第二行开始写入数据
for j in range(len(data)):
insertData = [data[j]["id"], data[j]["name"], data[j]["price"]]
row = 'A' + str(i)
worksheet1.write_row(row, insertData)
i += 1
workbook.close() # 关闭表
# "-------------数据用例-------------"
testData = [
{"id": 1, "name": "立智", "price": 100},
{"id": 2, "name": "维纳", "price": 200},
{"id": 3, "name": "如家", "price": 300},
]
fileName = '测试.xlsx'
xw_toExcel(testData, fileName)
 wechat
wechat- alipay











