爬虫(二):响应解析
当你获取响应文件后,你需要做的就是收集其中的关键信息。对不同的响应文件格式你需要选择不同方式解析。
下面是一些常见的响应解析方式
一. Xpath
1. Xpath基础
Xpath适用于解析HTML格式文件,并且语法及其简介。
2. 对str对象使用Xpath
对于一般的HTML格式响应对象 response.text() 是字符串类型,因此在使用之前: from lxml import etree
3. Xpath语法
这里先举个例子(也是我开始学爬虫的测试网站)
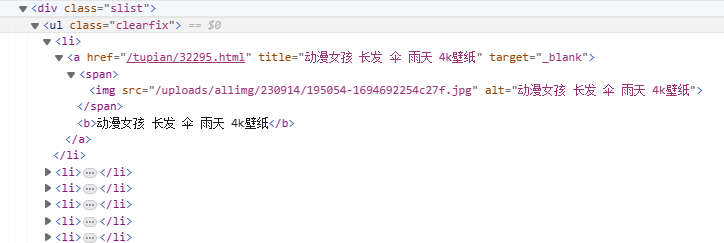
如果你想拿到 a标签 的href属性://div/ul/li/a/@href
如果你想拿到 img标签 的src属性://div/ul/li/a/span/img/@src
如果你想拿到 b标签 的内容://div/ul/li/a/b/text()
//div能够锁定所有div标签,这也是经常使用的Xpath开头,当然你也可以明确定位一个标签//div[@class=’slist’]
下面是详细语法
/:子标签
//:子孙标签
@:取属性
text():取内容
二. JSON
1. JSON基础
json用于解析json类型格式响应,这是非常普遍的,在异步加载的网页中,很多后端数据通过json格式传到前端进行渲染,得到浏览器显示的HTML文件。比如微博。
2. Python字典处理JSON
Python字典和Java对象很相似,Json(JavaScript Object Notation)也可以通过python字典进行处理。
comment_json = json.loads(response.text)
3. Python字典语法
这个很简单…
额..还是记一下吧
user = {
'uid': ''
'username': ''
'password': ''
'friends': []
}
dict[“xxx”]:取字典中xxx
三. BS4
1. bs4基础
2. 引入bs4
from bs4 import BeautifulSoup
3. bs4语法
soup = BeautifulSoup(resp.content, 'html.parser')
tag_div = soup.find_all("div",class_='result c-container xpath-log new-pmd')
link = i.get('mu')
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 良月的小窝!
 wechat
wechat- alipay


相关推荐






评论
ValineDisqus



